Automatisch tellen op luchtbeelden: aardbei bloemen

Automatisch tellen op luchtbeelden: aardbei bloemen
Het kweken en oogsten van aardbeien is een arbeidsintensieve bezigheid die bemoeilijkt wordt door de onvoorspelbare en variabele opbrengst van aardbeiplanten. Opbrengstvoorspelling is dan ook een belangrijk aspect bij het cultiveren van aarbeien om logistieke redenen, zoals het voorzien van voldoende personeel, transport, verpakking, en opslag. In dit artikel lees je hoe dronedata ingezet kan worden om een automatische oogstvoorspelling uit te voeren.
Uit verschillende onderzoeken blijkt dat het aantal bloemen een goede maat is om de opbrengst van aarbeien te voorspellen: een bloem vandaag is gemiddeld gezien een rijpe aardbei 3 weken later. Het tellen van bloemen is echter ook arbeidsintensief en onmogelijk uit te voeren voor grote oppervlaktes. Het selectief tellen van kleine zones om die tellingen dan te extrapoleren over het hele veld is dan weer erg gevoelig voor de van nature aanwezige variaties in de groei en bloei van deze planten, veroorzaakt door minutieuze verschillen in onder andere temperatuur, belichting, bevloeiing, bemesting en ondergrond.
Met moderne technieken voor artificiële intelligentie voor beeldverwerking is het echter mogelijk het tellen van aardbeibloemen te automatiseren. Het gebruik van (al dan niet geautomatiseerde) drones voor het opnemen van de beelden voor deze tellingen laat toe snel en efficiënt grote oppervlaktes te verwerken, en gedetailleerde oogstvoorspellingen te genereren voor volledige velden. Verder genereren deze technieken ook bijkomende informatie, zoals dichtheidskaarten voor bloeiende bloemen en de evolutie hiervan in de tijd, wat onmisbare informatie kan zijn voor optimalizatie van de groei (bemesting, bewatering, …).
Verzamelen van gegevens
Om deze artificiële intelligentie methodes te ontwikkelen en te testen hebben we in eerste instantie genoeg data nodig over de groei en bloei van aardbeien. Hierin zijn we bijgestaan door Proefcentrum Fruitteelt VZW, waar proefvelden voor de aardbeiteelt aanwezig zijn. De focus lag hierbij vooral op 5 rijen aardbeiplanten van elk 50m lang en ongeveer 150 planten per rij. Deze planten zijn allemaal van dezelfde variëteit “Varity”, maar hebben verschillende behandelingen ondergaan waardoor lokale verschillen in de groeistadia aanwezig zijn.
Van dit proefveld zijn verschillende opnames gemaakt met drones, verspreid over 15 weken tijdens de bloei en oogst van de aardbeien. Deze beelden zijn ook genomen met verschillende hoogtes variërend van 2 tot 20m hoogte, in verschillende weerscondities, en in open lucht en binnen in serres. Telkens zijn ook van dezelfde 12 selecties van 30 planten de bloemen manueel geteld, om op die manier een grondwaarheid te bekomen en de automatisch getelde hoeveelheden te kunnen valideren.
Het verzamelen van de dronebeelden en de initiële dataverwerking zijn uitgevoerd door een extern dronebedrijf (Didex). De bekomen beelden tonen een grote overlap en werden samengevoegd in één grote orthografische foto. Een voorbeeld van zo een orthofoto van de 5 rijen van 50m lang is hieronder gegeven. Let op dat dit een sterk verkleinde versie is, en dat het originele beeld een erg hoge resolutie heeft.

Een samengevoegde en gerectifieerde orthofoto. Het volledige beeld heeft 3600 x 22500 pixels.
Selectie van het algoritme
Het geautomatiseerd tellen van personen of objecten in beelden is een veelvoorkomend en populair probleem in beeldverwerking, met een rijke literatuur en veel verschillende benaderingen en algoritmes. Recente overzichten kunnen gevonden worden in volgende links:
- CNN-based Density Estimation and Crowd Counting: A Survey. https://arxiv.org/pdf/2003.12783.pdf .
- A Survey of Recent Advances in CNN-based Single Image Crowd Counting and Density Estimation. https://arxiv.org/pdf/1707.01202.pdf
- Convolutional-Neural Network-Based Image Crowd Counting: Review, Categorization, Analysis, and Performance Evaluation. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6983207/
Uit deze overzichten is het duidelijk dat er honderden recente papers zijn die gaan over het tellen van personen of objecten. Een klasse van methodes die vaak terugkomt en systematisch goede resultaten behaald is gebaseerd op een convolutioneel neuraal netwerk (CNN). Dit type van neuraal netwerk is de laatste tien jaar erg populair geworden binnen artificiële intelligentie, en vormt ook de basis van veel recente ontwikkelingen zoals “deep learning”. Omdat er ook binnen de klasse van CNN-gebaseerde telmethodes veel mogelijkheden bestaan hebben we gekozen voor een relatief simpele methode die toch goede resultaten oplevert en vaak geciteerd wordt in de literatuur: https://www.cs.tau.ac.il/~wolf/papers/learning-count-cnn.pdf
Annotatie en bloemdichtheid
Algoritmes gebaseerd op CNN zijn voor de meeste toepassingen gesuperviseerde algoritmes. Dit betekent dat het algoritme probeert te leren uit voorbeelden, en zal nabootsen wat het gezien heeft tijdens een trainingsfase. In eerste instantie is het dus noodzakelijk een grote hoeveelheid voorbeelden te genereren van wat men verwacht van het netwerk, de zogenaamde trainingsset. In ons geval zal de trainingsset bestaan uit een foto als invoer, en een telling als uitvoer. Dit kan echter op vele manieren aangepakt worden.
Ten eerste moeten we een beslissing nemen over de grootte van de beelden. Een gigantische foto in één keer verwerken is niet opportuun, en typisch zal men bij deze technieken een grote foto automatisch opdelen in kleine stukjes van dezelfde grootte. De totale som over de hele foto is dan de som van de tellingen in de individuele stukjes.
Verder moeten we een grondwaarheid opbouwen, en dit vereist het manueel annoteren van een groot aantal foto’s. Deze arbeidsintensieve taak kan aangenamer gemaakt worden door gebruik te maken van annotatiesoftware. Dit annoteren kan ook op verschillende manieren gebeuren: Men kan bijvoorbeeld het aantal bloemen aanduiden op elke foto, men kan elke bloem aanduiden met een enkele klik in het midden van de bloem (punt-annotatie), of men kan met een vierkantje elke bloem aanduiden, wat dan ook informatie geeft over de grootte van de bloem (box-annotatie). Voor het geïmplementeerde algoritme volstaat punt-annotatie.
Een bijkomend probleem van annotatie is dat deze niet uniek is. Indien hetzelfde beeld tweemaal geannoteerd zou worden zal het resultaat lichtjes variëren. Bij punt-annotatie bijvoorbeeld zullen de coördinaten van elk punt niet exact overeenkomen, en kleine verplaatsingen van de punten zullen toch nog een geldige annotatie opleveren. Daarom is het niet gewenst de exacte coördinaten te leren van elk punt, maar eerder het concept dat er in die omgeving één of meerdere punten zijn. We wensen dus eerder een punt-dichtheid te leren. In de praktijk kan dit worden bekomen door de punten te vervagen met een Gaussische functie waardoor een puntenverdeling wordt omgevormd tot een dichtheidsfunctie. Deze is minder gevoelig voor kleine verplaatsingen of verschillen in annotatie, terwijl we toch nog een telling kunnen uitvoeren: De som van de dichtheid over alle pixels zal nog steeds hetzelfde aantal opleveren als de initiële punt-annotatie.
Een voorbeeld van dit annotatieproces is hieronder getoond. Zie ook het artikel over annotatie in de EUKA drone-tech-blog hier: https://euka.flandersmake.be/dataverzameling-voor-ai-waarom-diversiteit-van-beeldmateriaal-zo-belangrijk-is/

Van links naar rechts: Een beeld uit de data set voor annotatie. Het manueel geannoteerde beeld waarbij 4 bloemen zijn aangeduid. Het resulterende logische beeld met de coördinaten van elke annotatie. En finaal de puntenwolk die herleid is tot een dichtheidsmap via een Gaussische functie. De som over het hele beeld is nog steeds 4, maar de exacte locatie van elk punt is minder van belang.
Een kwalitatieve en grote dataset is erg belangrijk, gezien het netwerk enkel relaties kan leren die ook aanwezig zijn in de trainingsset. Men moet echter de praktische afweging maken van het vergroten van de trainingsdata ten opzichte van de kosten hiervan in termen van verwerving van de beelden en werkuren voor verwerking, annotatie en opslag. Een bekende techniek om op een goedkope manier de trainingsdata toch te vergroten is data “augmentatie”: Met past simpele geometrische operaties toe, zoals spiegelen, schalen en roteren, welke nieuwe beelden opleveren waarvan ook de uitvoer kan berekend worden zonder menselijk ingrijpen. Let op dat in het voorbeeld hier de uitvoer een dichtheidsfunctie is, en dus de geometrische operaties ook op de uitvoer moeten worden toegepast.
Een voorbeeld van dergelijke geaugmenteerde data en de bijhorende uitvoer is gegeven in onderstaande figuren. Dit is ook de invoer en uitvoer waarmee het netwerk zal getraind worden.

32 typische beeldjes van grootte 128×128 pixels uit de trainingsset.
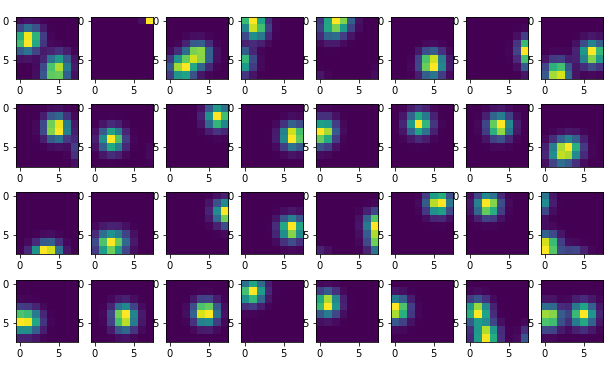
De corresponderende uitvoer als 8×8 dichtheidsbeelden.
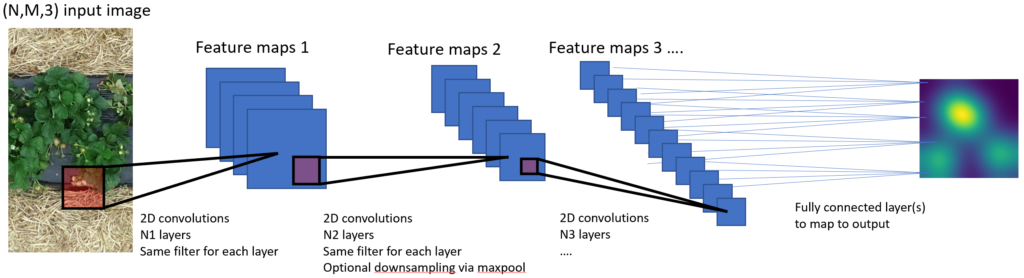
Het convolutioneel neuraal netwerk
Een convolutioneel neuraal netwerk bestaat meestal uit een sequentie van lagen, waarbij de uitvoer van elke laag de invoer vormt van de volgende laag. Er zijn verschillende types lagen, waarvan de belangrijkste de convolutionele lagen zijn (hieraan dankt een CNN dan ook zijn naam). Een convolutionele laag neemt een spatiale invoer, zoals een klein stukje van een foto, en past hierop verschillende filters toe. De uitvoer van elke filter vormt een kenmerk of “feature”, en het aantal kenmerken in een convolutionele laag is dus hetzelfde als het aantal filters in die laag. Typische filters gaan reageren op bepaalde vormen, kleuren, randen of patronen, en elke feature map zal dus een ruimtelijke beschrijving geven van hoe sterk die kenmerken aanwezig zijn in de foto.
Deze convolutionele lagen volgen elkaar sequentieel op, en de filters en kenmerken in elke laag worden zo complexer, abstracter en met een groter spatiaal bereik. Andere lagen wisselen soms de convolutionele lagen af, bijvoorbeeld pooling lagen die de resolutie verkleinen of volledig geconnecteerde lagen om de verbinding te maken met een uitvoerlaag. Tijdens het leerproces worden invoer-uitvoer paren gepresenteerd, en worden de interne parameters van het netwerk, zoals de verschillende filters in de convolutionele lagen, aangepast zodat de uitvoer van het netwerk zo min mogelijk verschilt van de gewenste uitvoer. De hoop is dat het netwerk zo de essentiële patronen leert herkennen om het probleem op te lossen, en deze dus ook zal kunnen toepassen op beelden die nieuw zijn.
Terwijl het trainen van een neuraal netwerk een intensieve taak is en uren tot dagen processortijd kan vragen, is het praktisch gebruik van een dergelijk netwerk veel minder intensief. Eénmaal getraind kan het netwerk snel en efficiënt ingezet worden in praktische scenarios: Het tellen van duizenden bloemen verspreid over honderden vierkante meter kan gebeuren in een tijdspanne van enkele seconden.
Resultaten
Als voorbeeld hebben we een volledige foto met 5 rijen van 50m aardbeiplanten geannoteerd. Deze vlucht nam plaats op een bewolkte dag op 10m hoogte. In totaal werden 741 bloemen aangeduid. De foto is dan geknipt in twee delen, waarvan één gebruikt werd voor training van het CNN, en het andere, ongeziene, gedeelte gebruikt werd voor het testen van het getrainde netwerk.

De volledige orthofoto, met aangeduid trainigngs- en testgedeelte.
Na de training van het netwerk gaan we na wat de prestaties zijn op het testbeeld. Deze performantie kan op twee manieren gevalideerd worden:
- Visuele inspectie van de gegenereerde bloemdichtheden, en vergelijking met de geobserveerde bloemen. Dit kan vereenvoudigd worden door het dichtheidsbeeld als een laag te plaatsen over het originele beeld.
- Het vergelijken van het aantal getelde bloemen door het CNN met het geannoteerde aantal.
Voor de eerste methode kunnen onderstaande beelden gebruikt worden. Links staat het testbeeld, rechts de gegenereerde bloemdichtheden als een rode laag over een grijswaarde versie van het kleurenbeeld. Visueel kan inderdaad nagegaan worden dat de overeenkomst erg goed is. Een ingezoomde versie, waarop ook de annotatie is aangeduid in groen, is ook gegeven.

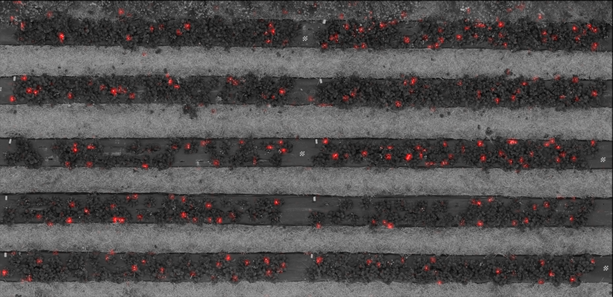
Het testbeeld als een RGB foto (boven), en de bloemdichtheid als een rode laag over een monochrome versie van het testbeeld (onder).

Een ingezoomde selectie van de bloemdichtheid en het testbeeld. Ter controle zijn de bloemen ook manueel geannoteerd, dit is aangegeven met groene punten. Het is duidelijk dat de overeenkomst goed is.
Het aantal getelde bloemen door de CNN is 267, het aantal manueel getelde bloemen is 254. De overeenkomst tussen beide resultaten is dus erg goed. Verdere testen op gelijkaardige beelden, en vergelijking met de grondwaarheid bevestigen dit gedrag.
CNN-gebaseerde telmethodes stellen ons dus in staat snel en automatisch tellingen uit te voeren van objecten in foto’s, wat we hier gedemonstreerd hebben met het tellen van aardbeibloemen op foto’s genomen met drones. Het knelpunt ligt in dit proces niet bij de beeldverwerking: Samengestelde foto’s die volledige velden met duizenden bloemen omvatten kunnen geteld worden binnen enkele seconden op een standaard laptop. Het correct verzamelen en verwerken van de beeldgegevens omhelst het grootste deel van de verwerkingstijd.
Dit artikel is ook verschenen op de EUKA Drone Tech Blog